Sonnet 5 vs. Opus 4.8: When the Cheaper Model Costs More
Sonnet 5 is cheaper per token than Opus 4.8, yet in a real Claude Code refactor it cost nearly twice as much. Why agent behavior, not price, decides cost.

Anthropic has just released Sonnet 5 and, on paper, it looks like a very interesting model for coding agents. It has the same 1M context window as Opus 4.8, it is positioned similarly fast, and most importantly, it is significantly cheaper per token.
So obviously I wanted to try it in Claude Code as soon as possible. Not on a synthetic benchmark, not on a toy repository and not on a task specifically designed to make one model look better than the other. I wanted to run it through the exact kind of work I do almost every day.
The result was a total surprise for me! Sonnet 5, the model that should have been cheaper, ended up being almost twice as expensive as Opus 4.8 for the same task.
Setting Up the Test
The setup was very simple. I created two different worktrees from the same repository. One worktree used Sonnet 5 and the other used Opus 4.8. Both had the exact same harness around them: same Claude Code rules, same skills, same tools, same MCP servers, same Serena setup, same repository context and the exact same prompt.
The task itself was a constrained refactoring task in a real .NET/Avalonia codebase. I had a resolved plan with seven concrete items, and both models had to implement those items without committing anything. This was not a product discovery workflow and it was not a vague “figure out what to build” prompt. The desired behavior was much simpler: understand the plan, implement it, respect the codebase conventions and stop.
That part matters because I think a lot of AI coding conversations still focus too much on whether a model can write code. At this point, the more useful question for me is how the model behaves when the boundaries are already defined. Does it stay inside the plan? Does it create extra work?
The Cost Difference
Sonnet 5 finished the session with an estimated cost of $11.67. Opus 4.8 finished the same task with an estimated cost of $6.10. That is a $5.57 difference on a fairly small implementation task, and percentage-wise Sonnet was around 91% more expensive in this run.
The raw session stats explain why.
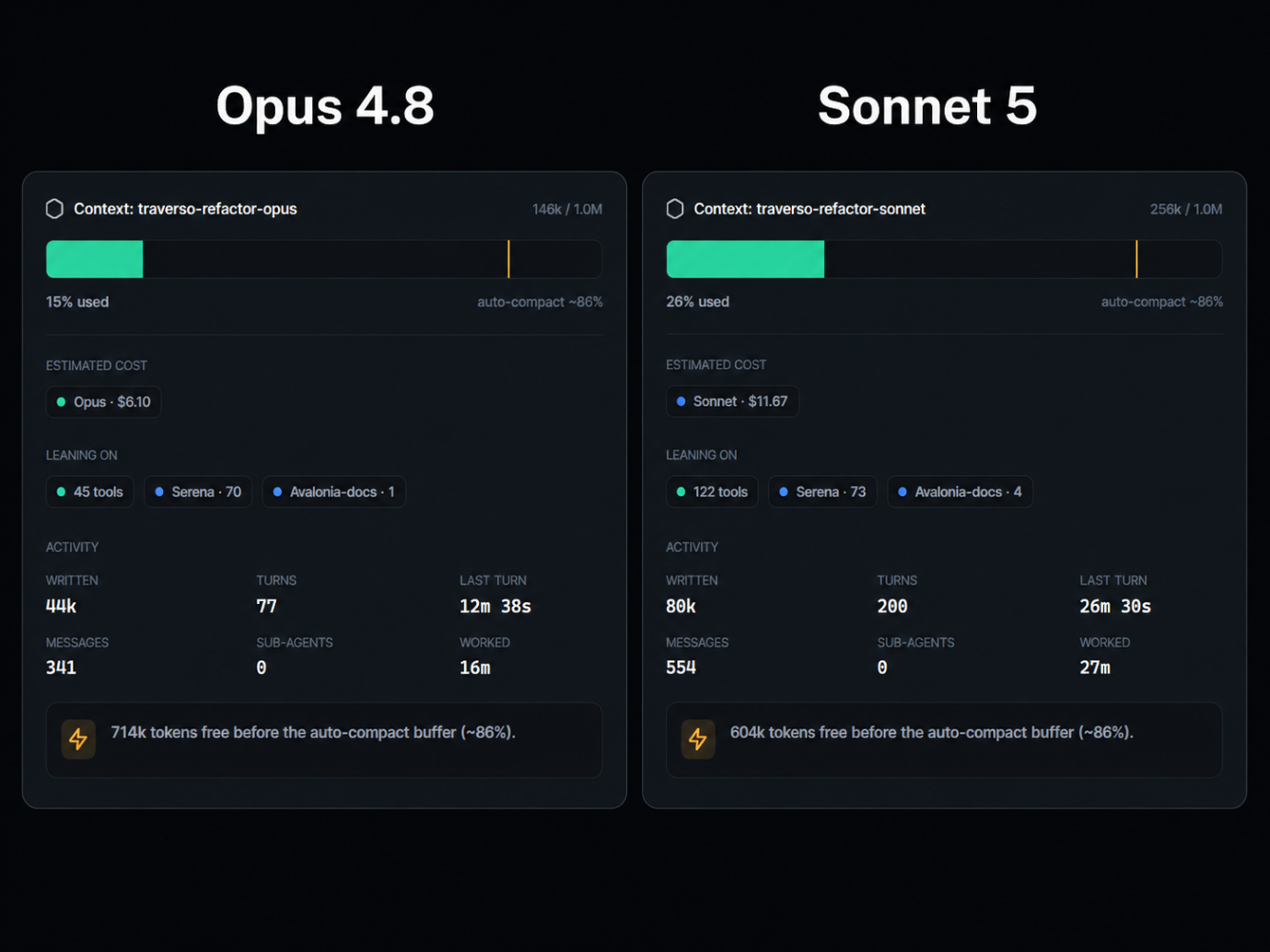
Sonnet used a lot more of everything. More context, more turns, more messages, more tool calls, more written output and more time. It used 256k tokens of context compared to 146k for Opus. It needed 200 turns compared to 77. It made 122 tool calls compared to 45.
This wasn’t because one model spawned a complicated sub-agent workflow while the other kept things simple. Both used zero sub-agents. They were both doing the implementation directly. The difference was simply in how much movement each model needed to get to the end.
Output Quality
The next question is whether the extra cost bought a better result. If Sonnet had produced a meaningfully better implementation, the cost difference would be easier to justify. That didn’t happen here, though.
I built and tested both worktrees myself. Both passed the full solution build. Both passed the full test suite. Both implemented all seven requested items. Neither committed anything.
To be honest, the convergence between the two implementations was probably the most impressive part of the whole test. For six of the seven items, the code was almost entirely equivalent. In some places it was basically byte-for-byte the same.
Both models also caught a trap in my plan. I had sketched a direct _logger.LogError(...) call, which would have failed this build because the project runs treating warnings as errors. CA1848 would turn that into an error and require source-generated logging delegates. Both models independently used [LoggerMessage] partial methods instead, which was the correct analyzer-clean approach.
So, this was not a case where Sonnet failed. It didn’t. Sonnet produced a correct implementation, built cleanly and passed the full test suite. The problem is that Opus did the same thing with less context, fewer turns, fewer tool calls, less written output, less time and a lower estimated cost.
The Difference That Decided It
Because both implementations were correct, the decision came down to scope discipline and cleanliness.
One of the seven items required computing HeatGrid once and passing it to three consumers. Opus made the minimal required change and moved on. Sonnet also implemented the requested change, but additionally extracted the trend-building loop into a new BuildTrends() helper.
That refactor was not wrong. It may even be a small readability improvement. But it was not asked for, and the repository rules are explicit about this: do only what was asked, with no “while I’m here” refactors.
This is one of those details that looks small on paper but matters a lot in real AI-assisted engineering. Extra refactors are not free. Even when they are technically fine, they create another decision for the human reviewer. Should this be part of the same change? Is it really better? Did it accidentally alter behavior? Should it be separated into another commit?
That is exactly the kind of review tax I try to avoid with the harness around my coding agents. When the plan is already resolved, I don’t want the model to be proactive in random directions. I want it to execute the plan carefully and stop. And Opus did that better.
Final Thought
Model pricing tables are useful, but they don’t tell the entire story for coding agents. In a normal API call, cheaper tokens usually mean cheaper execution. In an agentic workflow, the model’s behavior determines how many tokens, tool calls and turns are needed. A cheaper model can easily become more expensive if it takes a longer path to the same result.
FAQ
Why did Sonnet 5 cost more than Opus 4.8 if it is cheaper per token?
Because in an agentic workflow the model’s behavior decides how many tokens, turns and tool calls a task needs. Sonnet used 256k of context, 200 turns and 122 tool calls against Opus’s 146k, 77 and 45, so even at a lower per-token price the session added up to $11.67 versus $6.10.
Did the higher cost buy a better implementation?
No. Both worktrees passed the full build and the full test suite, implemented all seven requested items, and were near byte-for-byte identical on six of them. Both even avoided the same CA1848 trap by using [LoggerMessage] partial methods.
What actually separated the two models?
Scope discipline. Sonnet added an unrequested BuildTrends() refactor, while Opus made only the minimal change the plan asked for. The repository rules are explicit: do only what was asked, with no “while I’m here” refactors.
Do cheaper per-token models always cost less in coding agents?
No. A cheaper model can end up more expensive if it takes a longer path, with more turns, tool calls and written output, to reach the same result.